人工知能で発生前の台風のタマゴを見つける! – 30年分の雲の画像をディープラーニング
人工知能と気象データ
近年、毎日のようにニュースなどで「人工知能」という言葉を目にします。人間と同等の能力をコンピュータに持たせようとする人工知能の研究は、50年以上前から行われており、これまでにさまざまな手法が提案されてきました。
そのなかでも、ここ数年の大流行の中心にあるのは「深層学習(ディープラーニング)」です。ディープラーニングは、脳の神経細胞をモデル化したニューラルネットワークを多層化することで構築した、”ディープニューラルネットワーク”を用いる機械学習の手法です。
機械学習は、人間の学習にあたる仕組みをコンピュータ上で実現しようとするもので、何らかの対象を認識したり分類したりするためのルールをデータから自動的に学習することで、学習に用いていない新しいデータに対しても認識や分類を行うことができるようになります。ディープラーニングでは、大量のデータを効果的に学習することによって、画像や音声、文章などの認識や分類における複雑な処理ができるようになり、現在ではさまざまな場面で活用されています。また、ディープラーニングでは、データが多いほどより複雑なタスクを実行できることが知られています。
近年は、スーパーコンピュータや観測機器の性能向上や普及によって、膨大な量の気象データが蓄積されてきました。幸いにも私の周りには、すぐに扱える気象データがたくさんあったので、ディープラーニングを用いてどんなおもしろい研究をしようか、期待に胸を膨らませていました。数多くのテーマを思いつきましたが、そのなかでも最初に着手し、論文として出版されたのが、台風などの熱帯低気圧のタマゴを見つけようとするものです。
この研究の手法や結果の概要については、すでに海洋研究開発機構からプレス発表した記事にて紹介していますので、ここでは少し違った視点から本研究の難しさや解決策について触れてみようと思います。
熱帯低気圧のタマゴを見分ける難しさとは?
ディープラーニングの最も得意な仕事のひとつは、ものを分類することです。これは、入力された数字が0から9までのどれであるかを見分けたり、写真に写っているのが犬であるのか猫であるのか、またはキリンであるのかを見分けたりといった処理を指します。このような画像の分類に関しては、ディープラーニングはすでに人間の能力を超えているといわれています。私は、ディープラーニングを使って、専門家でも見分けるのが難しい問題に挑戦したいと思いました。
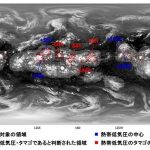
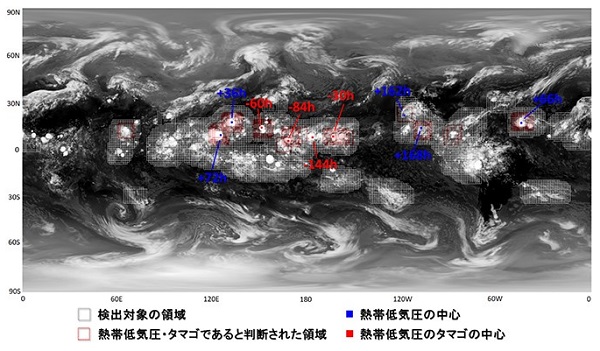
熱帯低気圧の雲は渦を巻いた特徴的な形をしているので、気象の専門家でなくてもすぐに見分けることができますが、そのような形状になる前のタマゴの状態となると話は別です。特に、発生の何日も前の状態のタマゴは、専門家でも正確に見分けるのは不可能となります。
私が最初に行ったのは、気象シミュレーションデータから熱帯低気圧または熱帯低気圧のタマゴが含まれる雲画像とそうでない雲画像を大量に切り出すことでした。30年分のデータから、熱帯低気圧またはそのタマゴの雲画像5万枚と、それ以外の雲画像100万枚を生成しました。

次に、数字を分類するのに使われるディープラーニングのサンプルプログラムを少し改良し、2万枚の雲画像(熱帯低気圧・タマゴ:1万枚、それ以外:1万枚)を用いて学習を行い、両者をどのくらい正しく見分けられるかテストを行ったのです。
私の作った非常にシンプルなプログラムでは、私の予想を超えて、約90%の確率で熱帯低気圧・タマゴの雲なのか、それ以外の雲なのかを見分けられるという結果が得られました。もう少し厳密にいうと、これは熱帯低気圧を熱帯低気圧であると見分け、そうでないものをそうでないと見分けることのできた確率です。
90%という結果を見て興奮したのも束の間、大きな問題に気が付きました。現実の状態を想像してみると、広い地球上で、熱帯低気圧またはタマゴの雲は多くてもせいぜい10数個であり、それ以外の雲は山ほどあります。私の作った分類器をある時刻の全球データに適用してみたところ、熱帯低気圧・タマゴの9割程度を見つけることができましたが、山ほどあるそれ以外の雲のうち1割程度も熱帯低気圧・タマゴであると間違えてしまったのです。
それではと、今度は熱帯低気圧・タマゴの雲画像1万枚とそれ以外の雲画像10万枚を学習させてみました。同様に全球のデータに適用してみたところ、今度は逆に多くの熱帯低気圧・タマゴの雲をそれ以外の雲と間違えてしまったのです。
重要なのは、熱帯低気圧・タマゴの雲を熱帯低気圧・タマゴである! とどれだけ正しくいえるか、そしてそれ以外の雲を、熱帯低気圧・タマゴである! とどれだけ間違えないか、の両者です。前者は捕捉率(または再現率)と呼ばれ、後者は空振り率(またはデマ率)と呼ばれます。

不均衡データを克服するには?
このように、小数派クラス(ここでは熱帯低気圧・タマゴの雲)と多数派クラス(それ以外の雲)のバランス差が大きいデータは「不均衡データ」と呼ばれ、特に少数派クラスに対する分類の性能が低下することが知られています。それでは、捕捉率を高め、空振り率を下げるためにはどのようにすればよいのでしょうか。
その解決策は、(1) 少数派クラスをうまく分類できるように重みを与えた学習を行う、(2) 多数派クラスのデータをうまく間引いて学習を行う、(3) 少数派クラスのデータを増やして学習を行う、の3つに大きく分けられます。
私が用いたのは(2)と(3)を合わせた手法で、10台のディープニューラルネットワークを用意し、それぞれ同じ熱帯低気圧・タマゴの雲画像5万枚と、それぞれ異なるそれ以外の雲画像5万枚を学習させました。そして、それぞれの分類器の結果をうまく取りまとめて最終的な分類を行うことにしました。こうすることで、一台一台の分類器では多数派クラスのデータを間引いて少数派クラスのデータを重視した学習を行いつつも、全体としては多数派クラスのデータも余すことなく学習することができました。
その結果、10年分の未学習データに対する平均では、北西太平洋の台風シーズンで捕捉率約80~90%、空振り率約30~50%という高い精度の数値を得ることができ、論文の出版に至りました。
空振り率の低下に向けて
上記の結果と並行して、他分野の専門家たちの知恵によって、熱帯低気圧・タマゴの検出性能を大幅に向上させようとする取り組みも行ってきました。そのひとつが、オンラインコンペティションの開催です。このコンペティションでは、私たちのグループが研究に用いたデータの一部をオンライン上で公開し、腕に覚えのある日本中の機械学習エンジニアまたは研究者たちが、そのデータを用いて自身の分類プログラムを開発し、空振り率の数値を競いました。
2018年8月から10月までの開催期間において、200名以上の方々が参加し、特に1位入賞者の開発したプログラムでは捕捉率を80%以上に保ったまま、空振り率を30%程に抑えることに成功しました。
熱帯低気圧だけでなく、集中豪雨や竜巻、または地震や津波など、自然現象において事前に予測したい、または前兆を検出したい現象は、発生頻度が少ない場合がほとんどです。また、世の中に目を向けても、ガンなどの病気の診断や工場生産における異常検出等、ほとんどのデータは機械学習にとって正しく分類するのが難しい不均衡データです。
オンラインコンペティションの開催は、他分野の不均衡データのクラス分類手法が、気象データにも応用できることがわかったという点でも大きな価値がありました。他分野の問題と気象学の問題において共通する部分を見つけ、その解決方法を柔軟に取り入れることが、人工知能時代の気象予測において必要不可欠になると考えています。
この記事を書いた人

-
国立研究開発法人海洋研究開発機構 付加価値情報創生部門 技術研究員、国立研究開発法人 科学技術振興機構さきがけ研究者。愛媛大学大学院理工学研究科博士課程修了、博士(工学)。
機械学習やデータ可視化等を初めとした情報科学技術の、地球科学ビッグデータへの適用に関する研究開発を行っています。