種子の形を機械学習で測る – シミュレーション画像を活用した教師データ作成で「植物フェノタイピング」を効率化
植物フェノタイピングとは?
これまで人類が経験したことのない気候変動と人口増加が続くなか、持続的かつ安定的な食糧増産を支えるためには、優良な品種を創出する技術を開発・運用していくことが喫緊の課題です。近年では、伝統的な交配育種だけでなく、ゲノム編集技術の利用や植物成長調整剤の開発、さらには土壌微生物叢の活用など、多様な手法を取り入れた技術開発が進められています。
どのようなアプローチにせよ、研究対象となる作物の形質を定量的・定性的な数値として算出し、客観的な評価が可能となる形に変換する作業は必要不可欠です。このような過程は、植物(plant)の表現型(phenotype)を測定することから「植物フェノタイピング(plant phenotyping)」1と呼ばれています。
従来、植物フェノタイピングは手作業での測定を主たる手段としてきましたが、さまざまな分野の技術革新の恩恵を受け、当該手法を活用する分野においても劇的な変化が観察されます。センサー・イメージング機器(ドローンやスマートフォンなど)の性能向上や価格の低下によって、データを簡便かつ多量に得ることが可能になりましたし、一方では、画像解析を行うためのソフトウェアライブラリの充実によって、データ解析のハードルが格段に下がりました。人間が手作業で測定していては到底時間、労力、そして予算が足りないような、これまでにない大規模なデータ解析が実現しつつあるのです。
特に最近では、深層学習を始めとする機械学習技術のうち、教師あり学習と呼ばれる方法が植物フェノタイピング分野において積極的に取り入れられはじめました。たとえば、病害虫診断や果樹中の果実の検出などにおいて、以前と比べて高い精度を達成することが容易となっています。このような方法では教師データと呼ばれる、コンピュータ2にとってお手本となる正解データ(ラベル)を人が用意します。するとコンピュータは、そのお手本と同じように画像を処理できるよう自身の精度を高めていきます。たとえば、病害虫診断プログラムを作るためには、作物の病気の画像と罹患している病気の名前をセットで用意しコンピュータに学習させる、といったようにです。
機械学習で種子の形状を抽出する
作物の種子形状測定をケース・スタディとしましょう。作物の種子の形(長さ、太さなど)は、作物の収量や品質と密接に関連のある重要な形質であることが知られており、品種改良における重要な評価尺度です。しかしながら、小さな種子一粒一粒の形状を手で計測することは非常に困難な作業です。
そこで解決策として、「インスタンス・セグメンテーション」と呼ばれる、物体ごとの存在領域を抽出することができる機械学習の活用を考えてみます。このような手法を利用すると、下図のように、1枚にある無数の種子をひとつひとつ認識し、その大きさや形を自動的に測定することが可能となります。

教師データの作成は大変
インスタンス・セグメンテーションは、一般に教師あり学習に分類されます。本題材における教師データの正解ラベルとは、画像内の種のすべての輪郭を囲い、さらに内側を色塗りしたデータを意味します。しかし、数の多い物体の教師データの作成は非常に手間がかかります。
たとえば、品種ごとに数十~数百の画像を用意し、それぞれに対して数百の種子を一粒ずつ色塗りするような作業が求められます。たとえ技術的に可能であったとしても、大量の教師データの作成は時間・労力の点から現実的ではありません。「教師データを作っていたら、研究プロジェクトが終了していた」「教師データだけで研究に必要なデータが取れてしまった」などという笑(えな)い話もあったりなかったりします。

シミュレーション画像を活用して教師データを作成する
ところで、ロボットや車の自動操縦の開発に取り組む分野では、シミュレーションデータをうまく活用していることが知られています3。仮想空間上で生成した画像を利用して教師データに用いることで、いわばコンピュータの「イメージトレーニング」を行う方法です。私たちの研究グループも、このようなアプローチに習い、種子画像の教師データを自動生成することにしました。
シミュレーション画像をより実際の画像らしくするため、少数の種をスキャンして、それらを仮想的な背景にランダムに配置することにしました。このようにして、私たちは「本物らしい」教師データを高速かつ大量に用意しました。
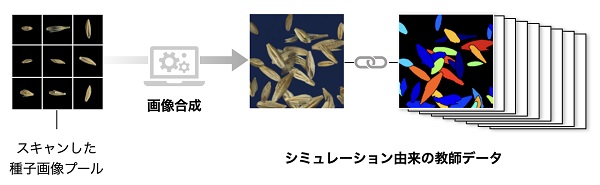
この教師データを用いてコンピュータを訓練したところ、手作業で測定するときと同程度の精度で、画像からの種子の検出と形状を抽出することが可能であることを示しました。ケース・スタディでは大麦を試用しましたが、同様の手法を用いることで、イネ、コムギ、えん麦、レタスなど多くの作物の種子を測定することができました。このことは、多様な種子を測るために必要十分な教師データを高速に作成する技術が確立できたことを意味します。

(Toda et al., 2020 Communications Biology. 図7より抜粋。Creative Commons 4.0.)
意義と今後の展開
大規模な気候変動が続くなかでの持続的な食糧生産のためには、育種(品種改良)のサイクルをスピードアップし、優良な品種を迅速に創出していくことが不可欠です。種子の形状を用いた品種の評価は、育種における強力な基盤ツールとなります。たとえば、無数の品種から収穫した種子の形状を一斉に測定することで、望みの形質を有するものを迅速に同定することができるでしょうし、また、品種内における種子の形質の安定性(ばらつきの程度)の議論も可能になるでしょう。
ところで、植物フェノタイピングを目的とした画像解析では、品種や部位、個体間での見た目の違いが大きい特性があるため、応用場面によって毎回異なる教師データを作成する必要があるのかもしれません。他の分野においてもそうですが、特に植物において教師データの作成は大きな悩みの種です。本研究で採用した、人工的な教師データ生成による手法は、さまざまな場面で活用することができます。今後、本研究における取り組みをきっかけとして、本研究の成果は作物種子の測定のみならず、植物表現型の計測のための機械学習を活用した画像解析プログラムの開発の高速化につながるものとして期待されます
本研究は、国際科学誌Communications Biologyに掲載されました。オープンアクセスであり、誰でも閲覧が可能なため、興味のある方は下記参考文献のリンクからアクセスください。
参考文献
Toda, Y., Okura, F., Ito, J. et al. Training instance segmentation neural network with synthetic datasets for crop seed phenotyping. Commun Biol 3, 173 (2020). https://doi.org/10.1038/s42003-020-0905-5
脚注
1. 植物フェノタイピングの対象は、葉や根の形など目に見える表現型だけでなく、光合成活性や栄養輸送能などセンサーを利用して初めて得ることのできるデータなど、幅広い対象をも含みますが、本稿では前者のみを指し示すものとします。
2. この文脈における「コンピュータ」とは、「機械学習モデル」ですが、わかりやすさのため前者の単語を使用するものとします。
3. 詳しく知りたい方は「Sim2Real: Simulation to Real」で調べてみてください。そのなかでも本研究は、「Domain Randomization」と呼ばれる手法を参考にしています。
この記事を書いた人
-
名古屋大学トランスフォーマティブ生命分子研究所 特任助教。博士(農学)。
株式会社フィトメトリクス 代表取締役。
名古屋大学農学部卒業、名古屋大学生命農学研究科博士後期過程修了、JSTさきがけ「 情報科学との協働による革新的な農産物栽培手法を実現するための技術基盤の創出」専任研究員を経て現職。



